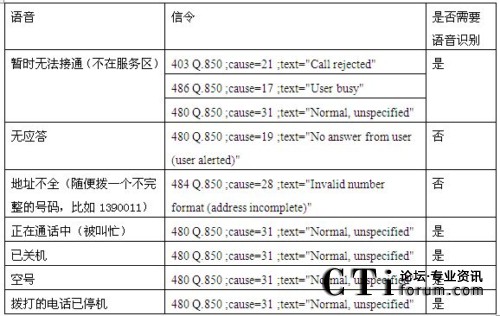
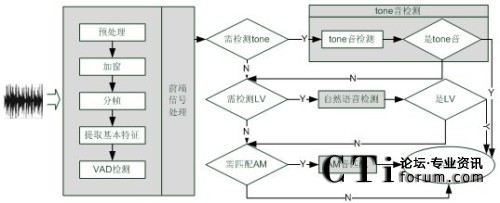
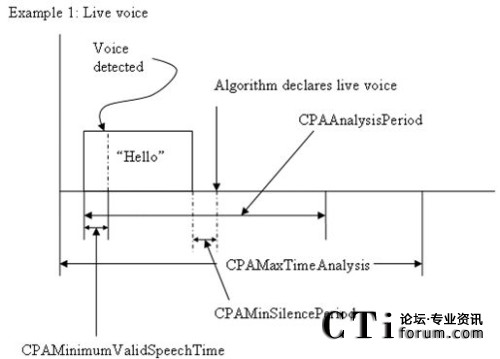
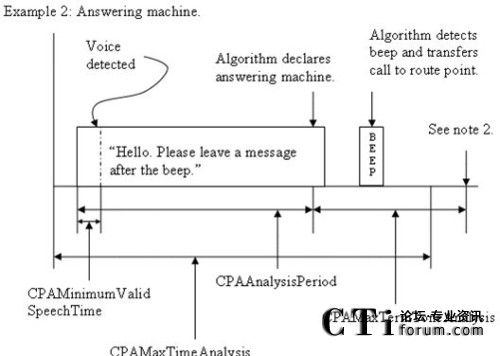
�Z���R(sh��)�e���g(sh��)���Ԅ�(d��ng)�����ϴ̖(h��o)ϵ�y(t��ng)�đ�(y��ng)���c��(y��u)��(sh��)
2011/07/18
ժҪ��

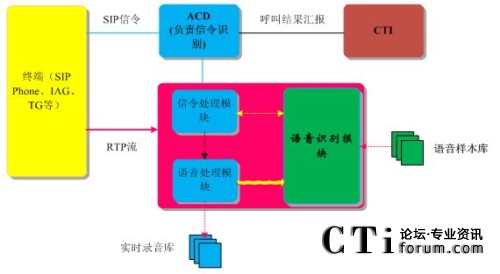
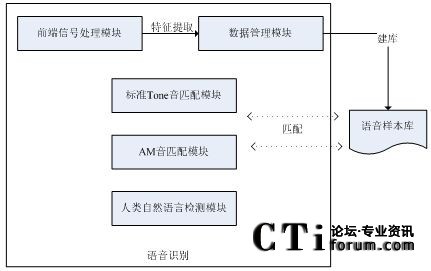
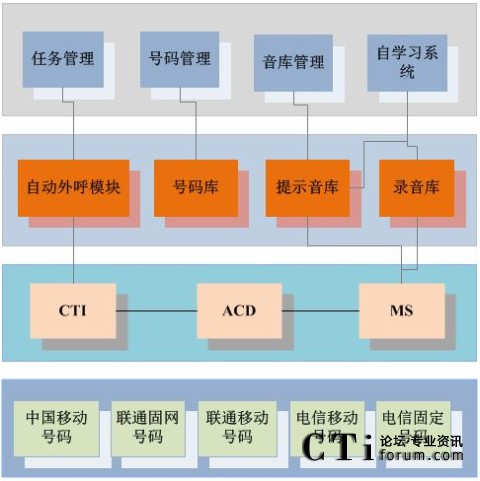
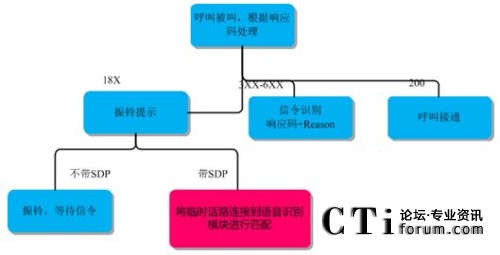
���߹��� CTIՓ����
| ���������н��ӱ����������������ϵ�y(t��ng) 2011-07-15 |
| �����������r(n��ng)�Ų���ITSM����(w��)ƽ�_(t��i) 2011-06-10 |
| �������^�W(w��ng)�P(gu��n)CIN-MG 2011-05-10 |
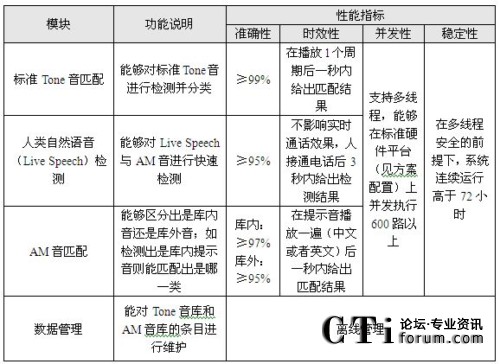
| ��������������ļ���N��I(y��)ϴ̖(h��o)ϵ�y(t��ng)���� 2011-05-09 |
| ������ý�w��������ϵ�y(t��ng)��Q���� 2011-05-06 |